2025. 3. 5. 03:30ㆍ데이터 엔지니어링 위클리

좋은 글
Trino로 타임아웃 개선하기
Trino로 타임아웃 개선하기 : NHN Cloud Meetup
Trino로 타임아웃 개선하기
meetup.nhncloud.com
Trino와 OBS를 도입하여 1억 건 이상의 집계 쿼리 실행 시 발생하는 타임아웃 문제를 해결했고, 집계 시간이 43% 단축되며 데이터 보관 기간이 60일에서 1년으로 연장되었지만 약 100만원의 추가 비용이 발생했습니다.
- 집계 쿼리 실행 시 목표 행(row)이 1억 건을 초과하는 문제
- Trino와 OBS(오브젝트 스토리지) 도입을 통해 해결
- 집계 시간 43% 단축, 데이터 보관 기간 60일에서 1년으로 연장
SmartThings, OpenSearch 도입으로 성능과 비용 절감
Samsung Tech Blog - SmartThings, OpenSearch 도입으로 성능과 비용 절감
이 글에서는 SmartThings 기록 시스템의 DB 교체 여정에 대해 소개합니다. 기존 HBase는 다양한 서비스의 요구를 충족하지 못해 SPOF 및 확장성 부족 등의 문제가 있었습니다. 이를 해결하기 위해 다양
techblog.samsung.com
HBase의 확장성 한계와 비용 낭비 문제를 극복하기 위해 OpenSearch를 도입, 시스템 안정성과 성능 개선으로 효율적인 운영을 달성했습니다.
- HBase를 사용했을 때 확장성이 부족하고 낭비되는 비용 문제
- HBase의 기능 제한으로 작업 지연이 발생되는 문제
- HBase가 단일 장애 지점이 되는 문제
LLM을 활용한 스마트폰 시세 조회 서비스 구축
LLM을 활용한 스마트폰 시세 조회 서비스 구축
LLM을 활용해 중고거래 게시글에서 스마트폰 정보를 추출하고, 이를 통해 시세를 산출한 방법과 벡터 DB를 이용하여 유사게시글을 제공한 방법에 대해 설명해요.
medium.com
LLM을 이용해 텍스트 정보를 추출하고 JSON 데이터로 변환, 사용자가 판매할 스마트폰의 적정 가격을 손쉽게 확인할 수 있도록 돕는 서비스를 구축했습니다.
- LLM을 활용한 스마트폰 시세 조회 서비스 구축 유저가 판매할 스마트폰 가격 설정에 어려움을 겪는 문제가 있음
- LLM을 통해 텍스트에서 정보를 추출하고, 이를 JSON 데이터로 변환하여 시세 정보 제공
Data engineering my way through new parenthood
Data engineering my way through new parenthood
My first child was born on September third, and my whole life flipped completely upside down. Suffice it to say that the cliches from…
medium.com
개인 육아 데이터를 추적하고 시각화함으로써 데이터 엔지니어링 접근법의 새로운 가능성을 제시하며, 실제 경험에서 우러나온 인사이트를 공유합니다.
Best Data Engineering 'Influencers'
From the dataengineering community on Reddit
Explore this post and more from the dataengineering community
www.reddit.com
다양한 플랫폼에서 활동하는 데이터 엔지니어 인플루언서들을 통해 최신 트렌드와 깊이 있는 인사이트를 얻을 수 있는 자료들이 모아져 있습니다.
- Daniel Beach: https://substack.com/@dataengineeringcentral
- Joe Reis: https://joereis.substack.com/
- Benjamin Rogojan: https://medium.com/@SeattleDataGuy
- Bryan Cafferky: https://www.youtube.com/@BryanCafferky
- Simon Spati: https://www.ssp.sh/categories/data-engineering/
- Maria Vechtomova: https://medium.com/@vechtomova.maria
- Data Janitor(Youtube): https://www.youtube.com/@thedatajanitor9537/videos
- Kahan Data Solutions(Youtube): https://www.youtube.com/@KahanDataSolutions/videos
- Charity Majors: https://www.linkedin.com/in/charity-majors/
- Simon Whiteley: https://www.linkedin.com/in/simon-whiteley-uk/?originalSubdomain=uk
- Alexey Grigorev: https://www.linkedin.com/in/agrigorev/?originalSubdomain=de
- Data with Zach: https://www.youtube.com/c/datawithzach
- 데이터 엔지니어 정보 모음: https://github.com/DataExpert-io/data-engineer-handbook?tab=readme-ov-file
How to Build Modern Data Architectures
이해관계자의 다양한 요구와 전략의 부재가 성과에 미치는 영향을 분석하며, 정기적인 보고서 리뷰를 통해 효과적인 데이터 아키텍처 구축의 중요성을 강조합니다.
- 이해관계자의 요구에 쫓기다 보면, 전략에 대한 고려 없이 무작정 진행하게 되고, 이는 전반적인 성과에 영향을 미친다.
- 보고서의 절반 이상이 사용되지 않거나 드물게 사용되고 있음을 알게 되었다. 데이터 팀은 정기적으로 보고서를 리뷰하고 관리하는 것이 필요하다는 점을 강조한다.
- 결과 중심의 데이터 엔지니어링(output-led data engineering)
- 여러 보고서에 재사용할 수 있는 구조적인 데이터 모델을 설정하는 것이 중요하다.
- 적은 수의 소스 테이블만을 식별하여 데이터 웨어하우스를 효과적으로 구축하는 목표를 갖는다.
- 기본적인 네이밍 규칙을 수립하고, 중요하게 여기는 소스 시스템에 대해서만 해당 규칙을 설정하는 과정이 포함된다.
Maximizing the ROI of Data Projects: A Practical Guide for Data Teams
Maximizing the ROI of Data Projects: A Practical Guide for Data Teams
How to Prioritize High-Value Data Initiatives and Demonstrate Their Impact in an AI-Driven World
blog.det.life
데이터 프로젝트의 가치를 매출 증가, 비용 절감, 생산성 향상 등으로 평가하는 실용적인 ROI 계산법을 통해 데이터 투자의 효과를 극대화하는 방법을 설명합니다.
- 데이터 프로젝트의 가치 평가 방법: ROI 계산하기
- (Value of project + Residual Impact) / (Cost to Acquire Data + Labor Hours + Cloud Costs)
- Value of Project
- 매출 증가: 데이터 프로젝트가 매출을 증가시키는 효과
- 비용 절감: 최적화 및 효율성 개선으로 인한 비용 절감
- 생산성 향상: 업무 속도 증가로 절약된 시간의 가치
- 고객 만족도 증가: 고객 유지율 및 매출 상승으로 측정 가능
- Residual Impact
- 장기적 매출 증가: 프로젝트 효과가 지속될 경우 예상 매출 증가
- 미래 비용 절감: 프로세스 개선을 통해 장기적으로 절약되는 비용
- 생산성 지속 향상: 시간이 지나도 계속되는 업무 효율 증가
- Cost to Acquire Data
- 데이터 구매: 외부 데이터 구매 비용
- 데이터 수집 비용: 하드웨어, 소프트웨어, 인건비 포함
- 데이터 라이선스 비용: 데이터 사용을 위한 라이선스 비용
The Future of Data Engineering: Trends to Watch in 2025
The Future of Data Engineering: Trends to Watch in 2025
As we navigate through 2025, the field of data engineering is undergoing significant transformations, driven by advancements in artificial…
medium.com
실시간 데이터 처리, AI 통합, DataOps/MLOps 및 분산형 데이터 관리 등 2025년 데이터 엔지니어링 분야의 주요 트렌드를 전망합니다.
- 실시간 데이터 처리 수요 증가
- AI를 위한 데이터 엔지니어링
- 지능형 데이터 파이프라인(AI + Data Pipeline): 데이터 품질 향상, 데이터 작업 자동화, 분석
- DataOps & MLOps
- Data Governance
- Data Mesh Architecture: 데이터 관리에 대한 분산형 접근 방식
Is Data Engineering Dying? The AI Takeover & The Future of Data Roles!
Is Data Engineering Dying? The AI Takeover & The Future of Data Roles!
For years, Data Engineers have been the Architects of scalable, robust Data pipelines. But with AI-driven automation making its way into…
blog.det.life
No Code ETL, 자동화된 쿼리 최적화, AI 기반 데이터 품질 모니터링 등 기술 발전이 데이터 엔지니어링 역할에 미칠 영향을 분석하며 미래 변화를 예측합니다.
- No Code ETL(AWS Glue DataBrew)
- 자동화된 쿼리 최적화(실행 속도 개선)
- AI 기반 실시간 데이터 품질 모니터링
- 데이터 거버넌스 및 규정 준수 자동화
Data Products: A Case Against Medallion Architecture
Data Products: A Case Against Medallion Architecture
The Significance of Medallion, Crux of the Differences between the two 3-Tiered DataFlow Models, and a Colourful Visual Journey!
medium.com
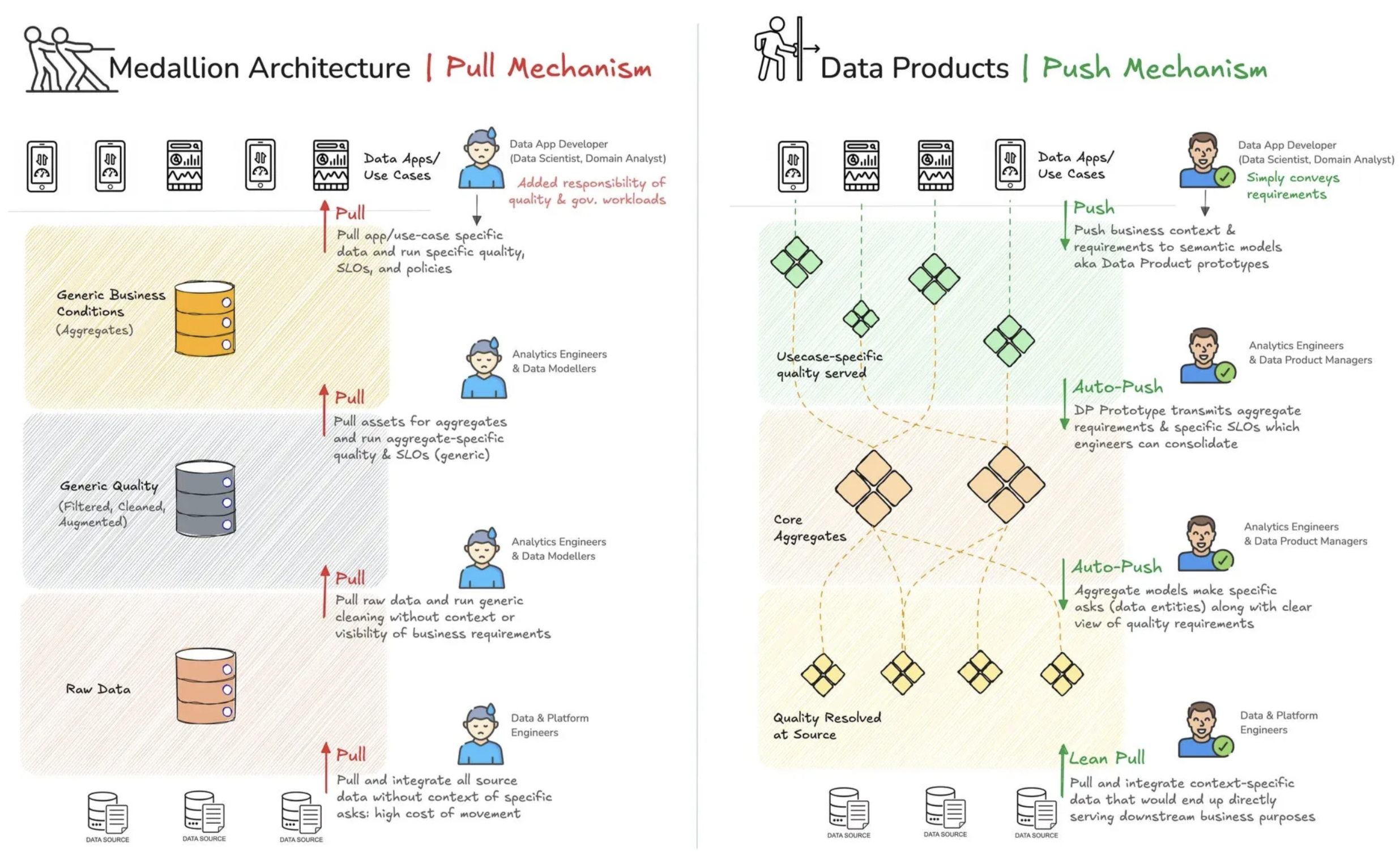
Medallion 아키텍처의 한계를 지적하고, 데이터 제품 아키텍처로 전환하여 비즈니스 중심의 유연하고 효율적인 데이터 관리를 실현할 필요성을 강조합니다.
- Medallion 아키텍처의 한계
- 겉보기에만 좋은 구조
- Medallion 아키텍처는 데이터 관리의 심리적 안정감을 주었지만, 실제 데이터 품질 문제를 해결하지는 못했다.
- 3단계 병목(Bottleneck) 형성
- 비즈니스 요구와의 괴리
- Data Product 아키텍처의 장점
- 데이터를 제품처럼 관리
- 도메인 중심의 데이터 관리
- 빠르고 유연한 접근
- Medallion 아키텍처의 레이어별 문제
- 강제된 브론즈
- 비용 증가 문제
- 품질 관리 없음
- 강제된 실버
- 비즈니스 요구사항 없이 정제
- 골드 계층에서 재작업
- 강제된 골드
- 비즈니스 계층과 가깝지만 여전히 비효율적
- 비즈니스와의 괴리로 인한 병목 현상
- 강제된 브론즈
- 해결책
- 비즈니스 중심의 데이터 아키텍처로 전환해야 한다
- 데이터를 단계별 변환이 아닌, 비즈니스 도메인 기반으로 구조화
- 데이터를 적극적으로 활용할 수 있는 방식으로 제공
- 데이터 거버넌스를 비즈니스 의미 중심으로 개선
Mastering Spark: The Art and Science of Table Compaction
Mastering Spark: The Art and Science of Table Compaction
If there anything that data engineers agree about, it’s that table compaction is important. Often one of the first big lessons that folks will learn early on is that not compacting tables can present serious performance issues: you’ve gotten your lakeh
milescole.dev
Spark 테이블 압축의 다섯 가지 방법을 소개하며, 자동 압축과 Optimized Write 조합이 최상의 성능을 발휘한다는 점을 실험 결과로 보여줍니다.
- 테이블 압축의 5가지 방법
- 압축 없음: 무한히 작은 파일이 쌓임
- 사전 쓰기 압축: 미리 적당한 크기로 씀
- 사후 수동 압축: OPTIMIZE와 같은 명령어로 압축
- 예약 압축: 스케줄로 OPTIMIZE 실행
- 자동 압축: 데이터가 작성될 때 자동으로 압축
- 측정 결과
- 자동 압축 + Optimized Write 조합이 가장 성능이 우수
- 옵션
- spark.databricks.delta.autoCompact.enabled 활성화 필요
- maxFileSize: 128MB
- minNumFiles: 50
릴리즈
Polars - v1.24.0
Release Python Polars 1.24.0 · pola-rs/polars
🚀 Performance improvements Provide a fallback skip batch predicate for constant batches (#21477) Parallelize the passing in new streaming multiscan (#21430) ✨ Enhancements Add lossy decoding to ...
github.com
- 성능 개선 사항
- 상수 배치에 대한 fallback skip batch predicate 제공
- 스트리밍 멀티스캔의 병렬 처리 최적화
- 주요 기능
- 비-UTF8 인코딩 CSV 파일 읽기 시 lossy decoding 지원
- DataFrame.write_iceberg 기능 추가
- rolling 연산(std, var, cov, corr)의 수치 안정성 개선
Trino - v471
Release 471 (19 Feb 2025) — Trino 472 Documentation
Add AI functions for textual tasks on data using OpenAI, Anthropic, or other LLMs using Ollama as backend. (#24963)
trino.io
- General 개선 사항
- 텍스트 데이터 처리를 위한 AI 함수 추가 (Ollama 백엔드 활용)
- EXPLAIN ANALYZE 출력에 split count와 전체 split 분배 시간을 포함
- 콘솔 로그 형식을 JSON으로 설정 가능 (log.console-format=JSON)
- Python UDF 지원 라이브러리 확대 및 성능 개선
- ORDER BY ... LIMIT 쿼리 성능 최적화
- 커넥터별 개선 사항
- Delta Lake 커넥터: variant 타입 읽기 지원, 로컬 파일 시스템 지원, 클론 테이블 읽기 지원, S3 저장 클래스 구성 및 대용량 체크포인트 파일 쓰기 문제 수정
- Hive 커넥터: 로컬 파일 시스템 지원, S3 저장 클래스 구성 지원, S3 glacier 복원 객체 읽기 문제 수정
- Hudi 커넥터: 로컬 파일 시스템 지원, S3 저장 클래스 구성 지원
- Iceberg 커넥터: 로컬 파일 시스템 지원, S3 테이블 지원, S3 저장 클래스 구성 지원, 동시 MERGE 쿼리 충돌 감지 개선, 파티션 테이블 쓰기 시 task.max-writer-count 설정 준수
- MongoDB 커넥터: 대소문자 구분 이름 충돌로 인한 실패 수정
'데이터 엔지니어링 위클리' 카테고리의 다른 글
| 데이터 엔지니어링 위클리 #6 | Knowledge Graph, Data Observability, OpenTelemetry, OpenLineage (0) | 2025.04.08 |
|---|---|
| 데이터 엔지니어링 위클리 #5 | Shift Left, Karpenter, Data 3.0, Lakehouse (1) | 2025.04.01 |
| 데이터 엔지니어링 위클리 #4 | LLM, AI, Netflix, Airbnb (0) | 2025.03.26 |
| 데이터 엔지니어링 위클리 #3 | 스파크 최적화, 데이터 제품, Late-Arriving Data (0) | 2025.03.19 |
| 데이터 엔지니어링 위클리 #2 | Data Lineage, SQLMesh, DBT, Synthetic Data (0) | 2025.03.11 |