2021. 3. 31. 23:12ㆍ데이터 엔지니어링
스노우플레이크(snowflake)
클라우드 컴퓨팅 기반 데이터 웨어하우징 회사이다. 2012년 7월에 설립되었고 2014년 10월에 공개적으로 출시되었다.
서비스로서의 데이터 웨어하우스(SaaS)를 제공해주며 복잡하게 구성된 데이터 웨어하우스를 완전관리 해준다.
빠르고 사용하기 쉽고 유연한 데이터 스토리지, 처리 및 분석 솔루션을 제공해준다.

AWS Snowflake
AWS에서도 스노우플레이크를 제공해준다. 일본 리전은 2018년에 생겻다.
aws.amazon.com/ko/financial-services/partner-solutions/snowflake-data-warehouse/
Snowflake Data Warehouse on Amazon Web Services (AWS)
Snowflake delivers the Data Cloud — a global network where thousands of organizations mobilize data with near-unlimited scale, concurrency, and performance. Inside the Data Cloud, organizations unite their siloed data, easily discover and securely share
aws.amazon.com
Snowflake Architecture: Service
- 중앙 집중식 관리
- 메타데이터 분리
- 전체 시스템에서 완전한 트랜잭션 일관성

ETL vs ELT
ETL이란 Extract, Transform, Load의 약어이다. 서로 다른 RDBMS에서 데이터를 추출한 후 변환하고 데이터 웨어하우스에 적재한다.
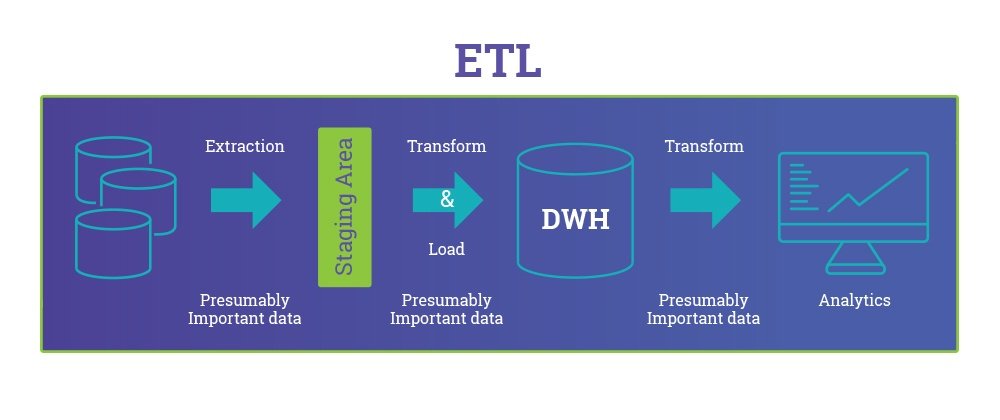
ELT란 추출해서 먼저 적재 후 적재한 곳에서 처리하는 방식을 말한다. 보통 대용량 처리에서 사용된다.

Snowflake가 하는 일
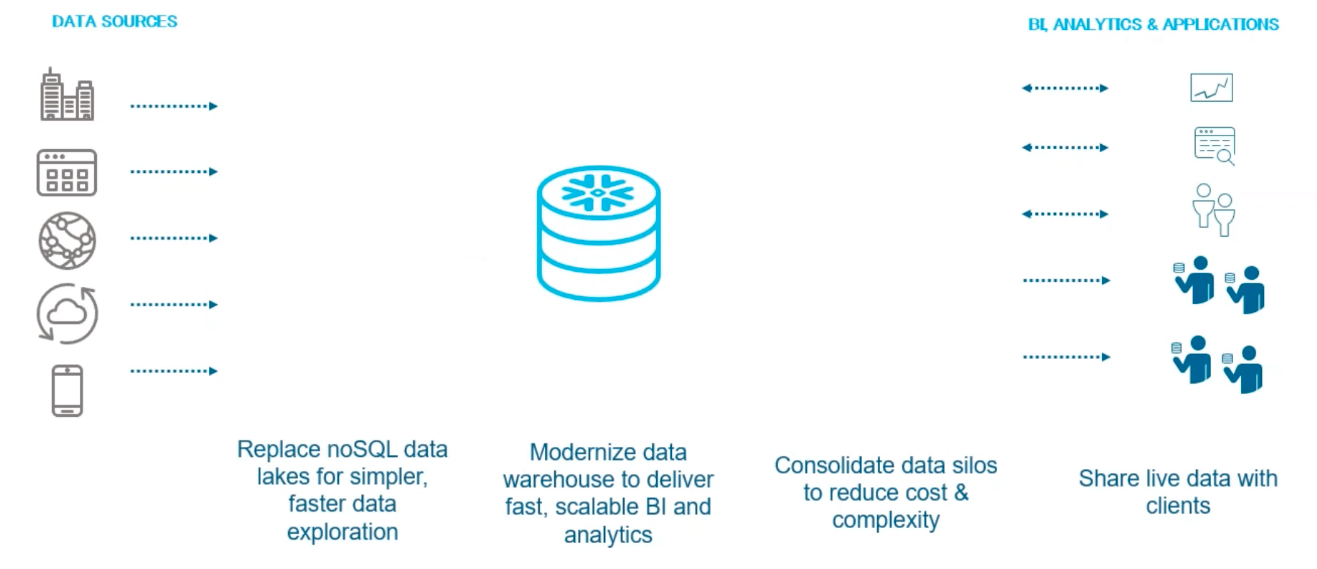
기존에는 아래의 그림처럼 STAGING, DTA LAKE, DATA WAREHOUSE, DATA MARTS & EXTRACTS가 서로 다른 곳에 분리되어 있었다.

Snowflake를 사용하면 하나의 플랫폼에서 이 기능들을 모두 처리할 수 있게 해준다.
- 더 간단하고 빠른 데이터 탐색을 위해 noSQL 데이터 레이크 교체
- 빠르고 확장 가능한 BI 및 분석을 제공하기 위해 데이터웨어 하우스 현대화
- 데이터 사일로를 통합하여 비용 및 복잡성 감소
Example
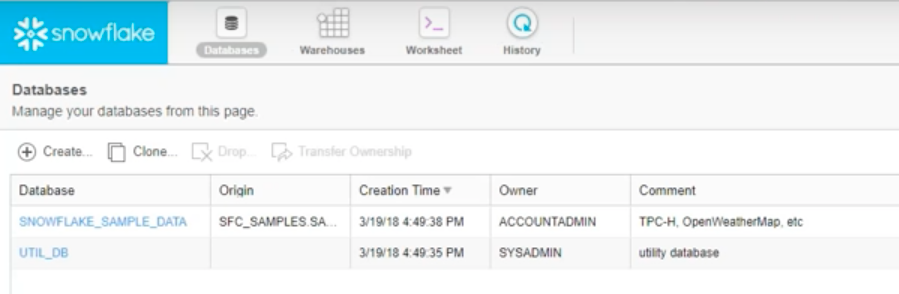
스노우플레이크 데이터베이스(Snowflake Database) 리스트 화면
스노우플레이크 테이블(Snowflake Table) 리스트 화면

스노우플레이크 워크시트(Snowflake Worksheet)

워크시트를 작성하고 실행하면 스노우플레이크에 테이블을 만들고 데이터를 넣는 등의 작업을 할 수 있다.
데이터베이스 IDE처럼 실행할 곳을 드래그로 부분만 실행할 수 있다.
위의 워크시트에서는 다음의 작업을 실행한다.
1. 스테이지 생성(URL=S3)
2. CSV_FORMAT 생성
3. 처리 후 넣을 테이블 생성
4. S3에 데이터 삽입(생성한 CSV_FORMAT, 스테이지 이용
COPY INTO CURATION.EVENTS
FROM @INGESTION.S3_STAGE/events/
FILE_FORMAT = (FORMAT_NAME = 'INGESTION.CSV_FORMAT');
6. SELECT를 해보면 삽입된 데이터를 확인할 수 있다.
SELECT * FROM CURATION.EVENTS LIMIT 10;
Curate Assets Data Example
데이터 큐레이션이란 데이터 수집과 정제 등의 과정에서 데이터의 가치를 높이기 위한 작업을 말한다.
1. 스테이지를 생성할 때 Snowflake, S3, Azure 중 하나를 선택할 수 있다. Snowflake를 선택한다.
2. 기존에 있던 Asset 데이터를 사용한다.

3. CURATION.ASSETS 테이블을 생성한다.
CREATE OR REPLACE TABLE CURATION.ASSETS (
ID STRING,
TYPE STRING,
ATTRIBUTES VARIENT, -- JSON DATA
CREATED INT,
CLIENT_ID STRING,
CLIENT_SFDC_ID STRING,
CLIENT_NAME STRING
)
4. 데이터를 삽입한다.
COPY INTO CURATION.ASSETS
FROM @INGESTION.INTERNAL_STAGE/assets/
FILE_FORMAT = (FORMAT_NAME = 'INGESTION.CSV_FORMAT');
Create Table for BI
1. 워크시트에서 아까 생성했던 테이블들을 조인해서 새로운 테이블을 만들 수 있다.
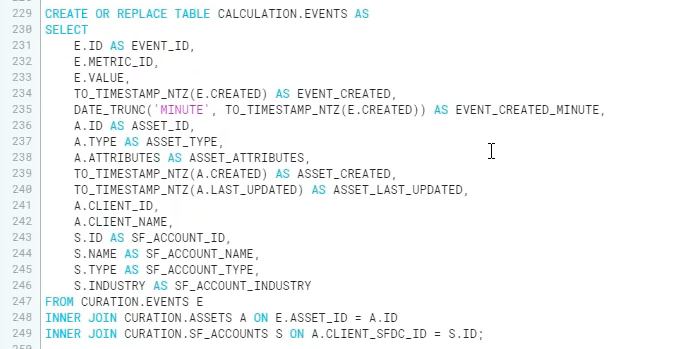
2. 이후 BI와 연동할 수 있다.
Warehuse

'데이터 엔지니어링' 카테고리의 다른 글
| [🧙Kafka] 카프카 구축 (1) - 주키퍼 앙상블 쉽게 구축하기 (2) | 2021.04.06 |
|---|---|
| [🔥Spark] Spark Streaming 이란? (0) | 2021.04.01 |
| [🧙Kafka] 카프카 정리 - 주키퍼(ZooKeeper)란? (0) | 2021.03.15 |
| [🧙Kafka] 카프카 정리 - 기본 개념 (0) | 2021.03.12 |
| [회사별 사례] 카프카(Kafka) 적용 사례(라인, 링크드인) (0) | 2021.03.10 |