| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 데이터 웨어하우스
- 에어플로우
- Parquet
- delta lake
- Schema Registry
- Data Warehouse
- kafka rest api
- 카프카 구축
- docker
- Redshift
- s3
- 스파크
- 스파크 스트리밍
- 컬럼 기반
- airflow
- kafka
- MySQL
- Data Engineer
- 델타레이크
- spark
- Zookeeper
- 데이터 엔지니어링
- Data engineering
- spark streaming
- 레드시프트
- 대용량 처리
- 데이터
- 데이터 엔지니어
- 카프카
- AWS
- Today
- Total
데이터 엔지니어 기술 블로그
[Kafka] 카프카 적용 사례(카카오, 트리바고) 본문
카카오의 카프카 적용 사례
RUBICS
출처: https://kakao.github.io/2016/04/27/rubics/
루빅스는 카카오의 추천 시스템이다.
2015년에 뉴스 기사를 추천하는 서비스에서 사용이되었으며 현재는 카카오 채널 등 다양한 콘텐츠에서 루빅스의 추천시스템을 사용하고 있다.
뉴스 서비스는 다른 콘텐츠에 비해서 생명주기가 짧기 때문에 사용자의 반응을 최대한 빠르게 수집 및 처리하여 추천 랭킹에 반영해야 한다.
실시간 데이터 처리
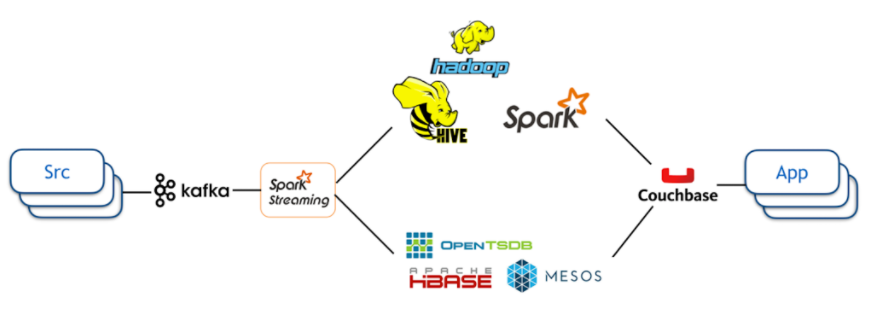
- 메시지큐: 카카오에서는 카프카가 데이터 손실을 방지해 줄 수 있으며 안정적이기 때문에 메시지큐로 사용했다.
- 데이터 스트림 처리기: 추천 랭킹을 위한 기계 학습에서 사용되며 Apache Spark Streaming을 사용하고 있다. 개발팀 내에 스칼라 언어에 익숙한 개발자가 많고 Apache Spark가 상당히 인기를 끌고 있었기 때문에 사용했다.
- 실시간 처리와 배치 처리로 분리: 굳이 실시간으로 처리할 필요가 없는 것은 배치 처리를 했다. 배치 처리를 위해서 Spark와 Hive를 사용했다.
빠른 응답 속도
- Disk, Network IO 발생 최소화
- 효율적인 알고리즘
- 병렬로 실행되는 코드
- race condition 문제를 해결하기 위해서 lock을 걸면 deadlock 문제가 발생할 수도 있다. 동시성 프로그래밍을 하기 쉬운 함수성 언어인 scala를 사용하여 어느정도 해결했다.
99%의 요청을 3ms 이내에 처리한다.
확장성
상태가 없는 구조로 설계하고 분산 NoSQL 데이터베이스인 couchbase를 사용하여 확장성 문제를 해결했으며 시스템 오픈 이후 60배 이상 트래픽이 늘고 20만 QPS(Queries per second)이 되어도 처리할 수 있게 되었다.
장애 내구성
- 루빅스를 상태가 없는 구조로 설계하여 특정 인스턴스에 문제가 생겨도 다른 인스턴스에서 이어서 처리할 수 있도록 한다.
- Couchbase를 사용하여 노드에 문제가 생겨도 분산 저장할 수 있는 기능을 제공하기 때문에 다른 서비스에 영향이 없도록 한다.
- Apache Mesos, Marathon, Apache Aurora를 사용하여 애플리케이션이 비정상 종료되어도 다시 실행될 수 있도록 한다.
- 마이크로 서비스 아키텍처에서 일부 구성요소에서 장애가 발생하더라도 다른 구성 요소로 장애가 전파되지 않도록 한다. 의존성이 있는 다른 구성요소에서 비정상 결과를 받을 경우 fallback 정책에 따라 기본값을 사용한다.
- 시스템 통합 테스트를 상시 진행하여 비정상적인 상황 발생시 개발팀 전체에게 알람을 보낸다.
기타
- 루빅스는 여러 알고리즘이 경쟁하는 구조이다.
- 루빅스는 실험을 하며 진화하는 시스템이다.
- 루빅스를 적용한 후 Daum 첫 화면 뉴스 노출이 다양해졌다.
KEMI
출처: https://kakao.github.io/2016/08/25/kemi/
KEMI(Kakao Event Maetering & monitoring)는 카카오 전사 모니터링 시스템이다. 서버, 컨테이너의 리소시와 메트릭 데이터를 수집해서 보여주고 임계치를 설정하고 그 임계치를 넘으면 알람을 보내주는 KEMI-STATS와 ETL을 통해 수집한 로그를 대시보드 형태로 보여주거나 실시간 알림을 해주는 KEMI-LOG로 구성되어 있다.

KEMI-STATS
카카오 전체 서버와 컨테이너 서비스를 모니터링하는데에 이용되며 polling 방식, push 방식 두가지를 사용한다.
- polling방식을 이용한 수집: physical machine, virtual machine, amazon ec2
- SNMP(Simple Network Management Protocol)를 이용하여 시스템 메트릭을 수집한다.
- 서버의 운영체제와 상관없이 모니터링하기 위해서 SNMP를 선택했다.
- 젠킨스 batch job을 이용해서 1분마다 수집한다.
- KEMI의 Poller가 각 대상들에게 시스템 메트릭을 가져와서 kafka에 저장한다. 어떤 매트릭을 수집할지에 대한 정보를 etcd에 가지고 있는데, etcd를 업데이트 하는 것으로 poller를 재시작하지 않고도 새로운 메트릭을 수집할 수 있도록 한다.
- 중간에 계산이 필요한 것은 apache samza를 통하여 계산 후 kafka에 넣는다.
- push방식을 이용한 수집: SNMP가 지원되지 않는 서버와 컨테이너 리소스 모니터링에서 사용하고 있다.
- 시간, 리소스 아이디, 시스템 메트릭을 EMI의 Stage Agg로 push한다.
- KEMI의 Stage Agg에서 Kafka에 저장한다.
- 계산이 필요한 메트릭은 EKMI의 Metric Calculator에 의해 계산되어 저장되고 그렇지 않으면 kafka에 바로 저장된다.
KEMI-LOG

KEMI-LOG는 각 서비스에서 발상한 로그를 저장하고 모아서 보여주고 룰에 따라 알람을 발생시켜준다.
- 각 서버에 설치된 fluented를 통해서 KEMI Aggregator로 보내지고 Hadoop과 Kafka에 각각 나누어 보낸다. Hive batch job을 통해서 5~15분마다 elasticsearch cluster로 indexing되어 kibana를 통해 사용자가 조회할 수 있게 된다.
- kafka에 저장된 데이터는 KEMI Dike를 통해서 알림을 발생시킨다.
기술과 장점
- fluented는 다양한 플러그인이 존재해서 로그 데이터를 변환해서 주고받을 수 있다.
- service discovery 도구인 consul로 관리되는 도메인을 바라보게 되어 있어서 각 서버에 있는 fluented 설정을 변경하지 않은채로 서버를 추가하거나 빼는 작업을 할 수 있다.
트리바고의 적용 사례
Better Log Parsing with Logstash and Google Protocol Buffers
출처: https://tech.trivago.com/2016/01/19/logstash_protobuf_codec/
트리바고는 로그 처리를 위해 ELK 스택에 의존한다. 웹 서버 액세스 로그, 오류 로그, 성능 벤치마크 등의 모든 데이터를 Kafka로 스트리밍하고 Logstash를 사용하여 Elasticsearch로 보낸다. 이 파이프라인에서는 Google의 프로토콜 버퍼를 사용한다.

Protobuf는 효율적인
직렬화 포맷이며 점점 더 많은 Kafka트래픽이 프로토콜 버퍼를 사용하여 인코딩되고 있다. JSON은 중괄호와 키 값 등 추가적인 문자열들이 필요하다. 그러나 스키마 구조가 크게 변경되지 않는 경우 자원 낭비가 클 수도 있다. Protobuf의 장점은 JSON과는 반대로 메세지가 짧다는 것이다.
로그스태시는 Protobuf를 이해하지 못하므로 트리바고에서는 루비를 사용하여 직접 플러그인을 개발하여 적용했다.
kafka
{
zk_connect => "127.0.0.1"
topic_id => "unicorns_protobuffed"
codec => protobuf
{
class_name => "Animal::Unicorn"
include_path => ['/path/to/compiled/protobuf/definitions/unicorn.pb.rb']
}
}